Why does my sales AI give generic answers?
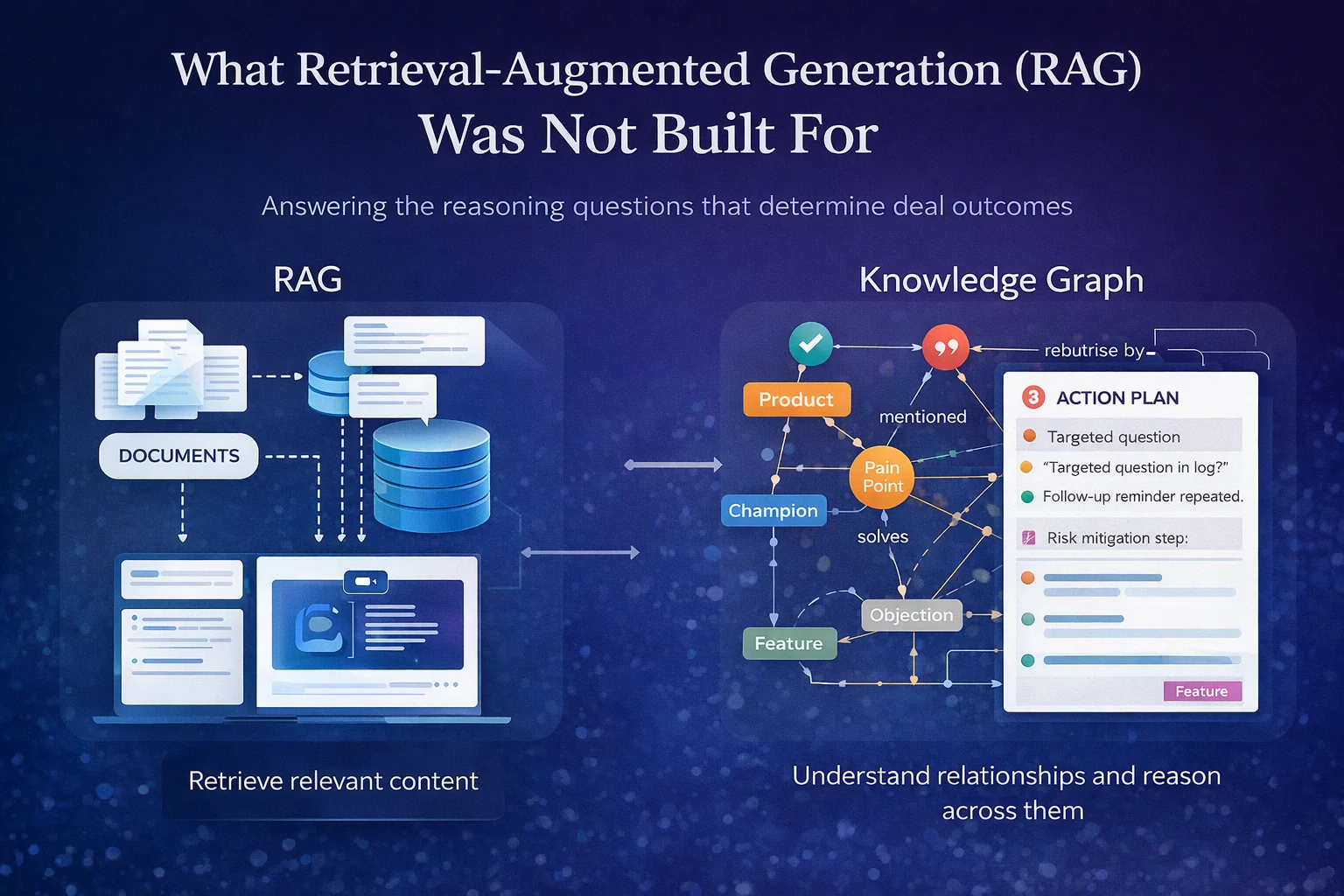
RAG was designed for retrieval questions. Revenue intelligence requires reasoning questions. Here is why the architecture gap matters for enterprise sales teams.

Retrieval solves one problem. Enterprise sales teams have a different one.
Most Revenue Intelligence tools today are built using RAG.
Retrieval-Augmented Generation was a genuine architectural step forward. By grounding language model outputs in external document corpora rather than parametric memory alone, RAG addressed hallucination and knowledge staleness in a practical, deployable way. The original Lewis et al. (2020) paper that coined the term demonstrated strong gains on knowledge-intensive tasks, and the pattern spread quickly across enterprise software. Most AI deployments in sales, HR, and support built on top of it.
The problem is not that RAG does not work. It is that RAG was designed for retrieval questions, and revenue intelligence requires answering reasoning questions. Those are different problems, and conflating them is where most enterprise AI deployments in sales quietly break down.
The retrieval question is: given a query, find the most relevant content. RAG solves this well. The reasoning question is harder: given everything that has happened in this deal, what does it mean and what should happen next? That requires not just finding relevant content, but understanding the relationships between entities, tracking how context evolves across time, and connecting what a prospect said three weeks ago to what a rep should do before Thursday's call. RAG was never designed to do that, and it shows.
What RAG Is Actually Doing
A standard RAG pipeline has three stages: documents are chunked and embedded into a vector index, a query retrieves the chunks with the highest semantic similarity, and a language model generates a response conditioned on those chunks. The ACM survey on GraphRAG methodologies (2024) identifies three structural failures in this approach for complex reasoning tasks: it neglects relationships between entities, it loses global context because only a subset of documents is retrieved at a time, and it produces what the authors call the "lost in the middle" problem where relevant information buried in retrieved context gets ignored during generation.
For a static knowledge base, these are manageable problems. For a system trying to reason over a live sales deal, they are fundamental.
The Relationship Problem in Sales
A CRM record is not a document. A stakeholder's engagement pattern across six meetings is not a document. The connection between a pain a prospect surfaced in week two, an objection they raised in week four, and the proof point that addresses both is not a semantic similarity problem. It is a graph traversal problem: find the relationship between these entities and reason across it.
Research on KG-RAG models (Scientific Reports, 2025) confirms that traditional RAG methods, which rely primarily on unstructured text corpora, are limited in their ability to handle complex relationships and perform multi-hop reasoning. In sales, multi-hop reasoning is the baseline requirement. Every useful pre-meeting briefing, qualification audit, and risk assessment requires connecting what was said to what it means for deal structure, which requires an architecture that understands relationships, not just text similarity.
This is why Microsoft's GraphRAG (2024) shifted the conversation. Rather than treating documents as flat text, GraphRAG builds entity-relationship graphs that enable theme-level queries with full traceability. The research example, querying supplier quality issues across relationships and time, is structurally identical to what revenue intelligence requires: querying deal health across stakeholders, qualification dimensions, and conversation history simultaneously.
The Statefulness Problem
RAG retrieves at query time and stops. Each retrieval is stateless: it has no memory of prior retrievals and no ability to track how context has evolved across interactions. Research on hybrid retrieval (Preprints.org, 2025) confirms that dense vectors are complemented by knowledge graphs precisely for structured contexts, because graph structures persist relationships across time in a way that vector indexes do not.
In sales this matters acutely. A deal is not a single document: it is a sequence of interactions where each one changes the meaning of the ones before it. A champion who attended every call in weeks one through four and then missed weeks five and six is not surfaced by a similarity search. It requires a persistent structure that tracks engagement patterns over time and flags the deviation. The same applies to qualification drift, evolving objections, and changing stakeholder composition. None of this is a retrieval problem. All of it is a state management problem.
The Lens Problem
Even when RAG retrieves correctly, it retrieves without context about why. A rep asking "what should I cover in this meeting" receives chunks most semantically similar to that query, not chunks most relevant to the specific deal state, the specific stakeholder profile, and the specific methodology gaps that define this conversation.
Brevian's architecture addresses this through what the product team describes as a lens constraint: the deal intelligence layer does not retrieve product knowledge generically, it queries everything from the lens of the conversation and the CRM. The distinction matters because the same product capability is more or less relevant depending on what has already been confirmed, what risks have been flagged, and where the deal is in the qualification framework. A flat retrieval system has no way to apply that constraint. A structured knowledge graph does.
The Access Control Problem
One operational dimension that rarely surfaces in technical RAG discussions is content classification. Research on naive RAG systems (MDPI, 2025) identifies retrieval inefficiencies, semantic mismatches, and context fragmentation as persistent production problems. But in enterprise sales there is a harder issue: not all content should be retrieved in all contexts. A pricing document, an internal battlecard, and a customer-safe case study all live in the same corpus, but surfacing the wrong one in the wrong context has real consequences.
RAG retrieves by semantic relevance. It does not natively understand the difference between internal knowledge and external-safe assets. That distinction needs to be a first-class property of the architecture, with content classified not just by what it says but by what it is and who should see it. A knowledge graph that treats asset classification as a node property can enforce this at query time. A flat vector index cannot.
What Changes When the Architecture Changes
The difference between RAG and a knowledge graph is not primarily about accuracy or recall. It is about what kinds of questions the system can answer.
RAG answers: what content is most relevant to this query? A knowledge graph answers: given everything we know about this deal, this prospect, and this methodology, what is the most important thing that needs to happen next? Those are different questions. The first is a retrieval problem. The second is a reasoning problem. And in enterprise sales, the second is the one that determines whether a deal closes.
When the architecture is built around relationships rather than retrieval, the outputs change category entirely. The intelligence that surfaces before a meeting is not the documents most similar to the meeting topic, but a structured assessment of where the deal stands, what has been confirmed, what gaps remain, and what the specific questions are that will advance it. The pipeline view that surfaces on Monday morning is not a list of records sorted by close date, but a scored assessment of each deal's structural integrity with a specific action for each one that needs attention before the week is out.
Retrieval is a component of that architecture. It is not the architecture.
Request a demo to see how Brevian's Knowledge Engine works with your data, your deals, and your methodology.
Brevian is the knowledge-powered sales intelligence platform that bridges the gap between product innovation and sales execution. Learn more at brevian.ai.
FAQ
What is Retrieval-Augmented Generation (RAG)?
RAG is an AI architecture that combines a language model with an external document retrieval system, allowing outputs to be grounded in a specific corpus rather than the model's training data alone. It was introduced by Lewis et al. (2020) and has become the dominant pattern for enterprise AI deployments in search, Q&A, and knowledge management.
Why does RAG fall short for sales intelligence specifically?
RAG is designed for retrieval questions: given a query, find the most relevant content. Sales intelligence requires answering reasoning questions: given everything that has happened in this deal, what does it mean and what needs to happen next? The ACM survey on GraphRAG (2024) identifies three structural failures in flat RAG for this kind of task: it neglects entity relationships, loses global context, and cannot perform multi-hop reasoning across retrieved chunks.
What is a knowledge graph and how is it different from a vector index?
A vector index represents documents as embeddings and retrieves by semantic similarity. A knowledge graph represents entities and the relationships between them, enabling the system to traverse connections and reason across multiple hops. For revenue intelligence, the relevant entities are products, features, pain points, stakeholders, objections, and qualification dimensions, and the relationships between them are what carry the intelligence.
What is GraphRAG and how does it relate to Brevian's approach?
GraphRAG, open-sourced by Microsoft in 2024, demonstrated that building entity-relationship graphs on top of document corpora dramatically improves reasoning capabilities for complex queries. Brevian's Knowledge Engine extends this principle specifically for the sales domain: the graph is built around the entities and relationships that determine deal outcomes, and the output is forward-looking action rather than retrieved content.
What is the access control limitation in standard RAG for enterprise sales?
Standard RAG retrieves by semantic relevance without natively distinguishing between internal and external-safe content. In sales, this creates risk: pricing documents, battlecards, and customer-safe assets coexist in the same corpus. A knowledge graph that treats content classification as a node property can enforce access control at query time, surfacing the right content to the right person in the right context.
If you liked this, you might want to read
From Prompt Loops to Multi-Agent Systems: Why the Harness Matters
Where the line between a prompt loop and a multi-agent system actually sits, and what that implies for the harness you have to build underneath.

Introducing Brevian MCP: What If You Could Ask Your Sales Data Anything?
New intelligence, synthesized from every layer of your sales data, delivered as operational playbooks you can act on this week.
Practice the Call Before It Happens
Every high-performance profession has structured practice. Sales is the exception. Brevian Roleplays let reps rehearse deal-specific scenarios grounded in real context.