From Prompt Loops to Multi-Agent Systems: Why the Harness Matters
Where the line between a prompt loop and a multi-agent system actually sits, and what that implies for the harness you have to build underneath.

Based on learnings from building Brevian
Based on learnings from building Brevian.
This post works through where the line between a prompt loop and a multi-agent system actually sits, and what that implies for what you have to build to move from one to the other.
Defining the two
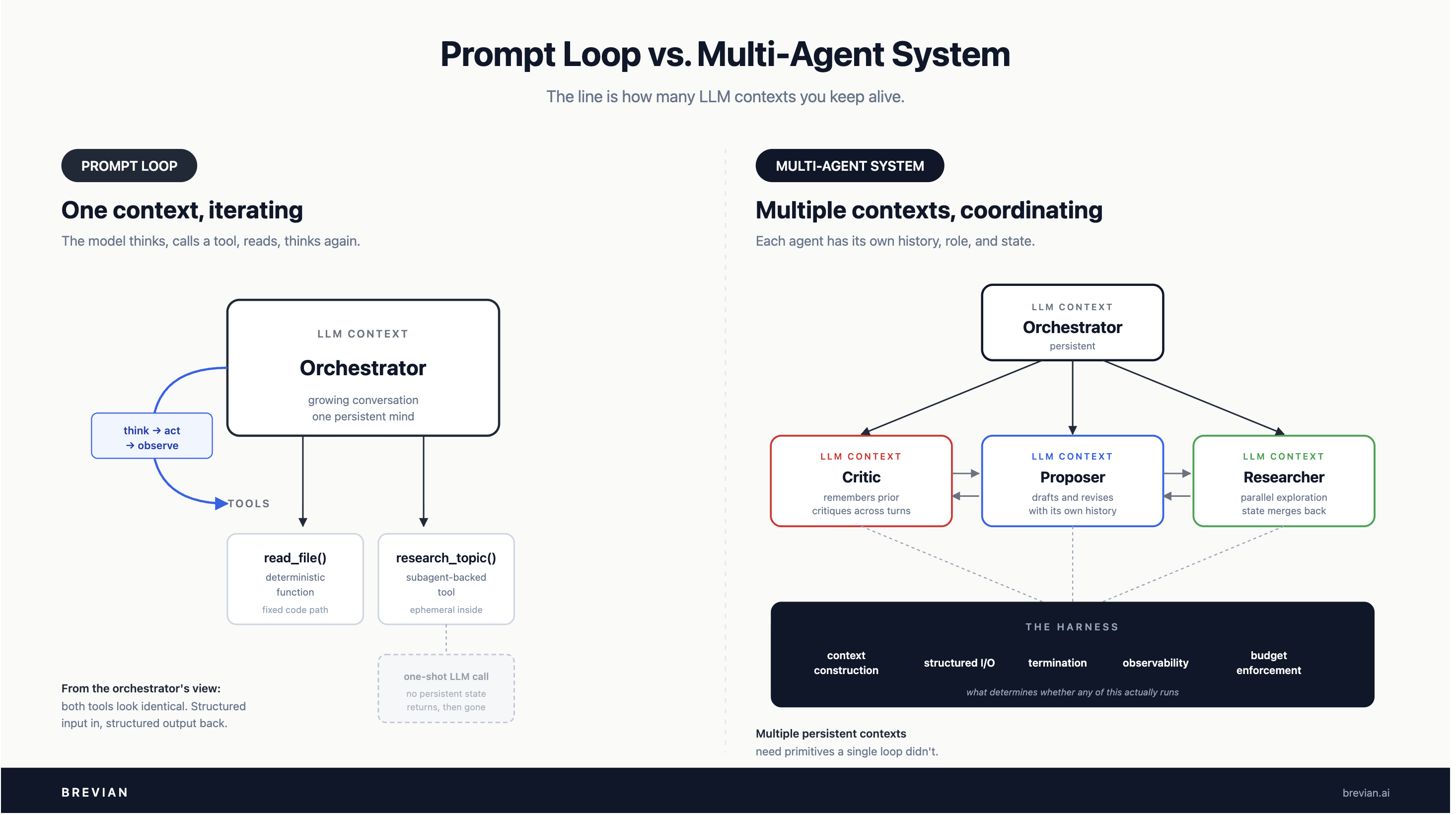
A prompt loop is one LLM context, iterating. The model thinks, calls a tool, reads the result, thinks again. One conversation, one growing context, until it terminates.
A multi-agent system has multiple LLM contexts that coordinate. Each has its own history, role, and state, and they exchange information somehow: messages, handoffs, or shared artifacts.
The follow-up question is what counts as an "agent." If a prompt loop can call tools, and one of those tools happens to wrap an LLM call internally, is that a multi-agent system?
Tools vs. agents
A tool is a deterministic function with a fixed code path and a predictable result. An agent is an LLM loop with its own reasoning and, usually, its own tools.
From the caller's perspective, the two are interchangeable. You invoke research_topic(query) and you get structured output back. Whether research_topic is a Python function calling an API or a full LLM loop with its own scratchpad doesn't matter to the orchestrator.
That symmetry lets you build an orchestrator that sees a flat list of tools, where some of those tools happen to do LLM reasoning internally. The orchestrator's code stays simple. The subagent's context, intermediate tool calls, and scratch work never enter the orchestrator. Only the final result comes back.
Which raises the next question. If the orchestrator can't tell the difference, is this a multi-agent system or a prompt loop?
Where the actual line is
The cleaner distinction isn't tools vs. agents. It's how many LLM contexts are involved, and whether they persist.
One LLM loop calling deterministic tools is a prompt loop. One LLM loop calling tools that wrap one-shot LLM calls is also a prompt loop. The subagent's context is ephemeral; it exists for one call and disappears. The orchestrator is the only persistent mind.
It becomes multi-agent when there are multiple LLM loops with their own ongoing state, coordinating across turns. A critic that remembers prior critiques. Agents that hand off control with their own state. Parallel agents whose intermediate states need to merge.
The orchestrator-worker pattern sits right on this line. It gets called "multi-agent" because subagents do reasoning, but architecturally it behaves like a prompt loop with rich tools.
Which side to build on
If the steps are known and deterministic, write a tool. If the steps require judgment, exploration, or chaining multiple actions, write an agent. If you'd write it as a function in normal code, it's a tool. If you'd write it as a prompt, it's an agent.
Default to tools. Every agent boundary adds latency, cost, and a new failure mode. Reach for a subagent only when the work needs reasoning the orchestrator shouldn't be doing itself: context isolation, a specialized prompt, parallel exploration.
A consequence of this is that work that gets called "multi-agent" can often be built as a prompt loop with subagent-backed tools. That keeps the orchestrator simple while still isolating context and specializing prompts per subtask.
Orchestration patterns
When you do need multiple agents coordinating, a few patterns recur.
Orchestrator-worker. A lead agent decomposes the task, dispatches to stateless workers, and synthesizes results. This is the orchestrator-with-subagent-tools pattern above.
Pipeline. Agents run in sequence, each transforming the previous output. Simple and predictable, with no backtracking. If step three reveals step one was wrong, there is no way back.
Parallel fan-out. Independent subtasks run concurrently, then merge. Good for embarrassingly parallel work. The cost is duplicated effort and merge conflicts.
Debate or critic loops. A proposer and a critic iterate until convergence, or several solvers compete and a judge picks. Improves quality on reasoning-heavy work at significant token cost.
Blackboard. Agents read and write a shared artifact instead of messaging each other. Useful when many contributors update one output. Needs conflict resolution.
Event-driven handoff. Agents trigger each other based on conditions. Closer to a workflow engine than a conversation.
Why the harness is what you're really building
The moment you introduce a second persistent context, or even subagent-backed tools doing real work, the harness has to do things the simple loop didn't need.
Context construction per agent. Each subagent should get the minimum context to do its job. Passing the orchestrator's full transcript into every worker burns the token budget. The harness needs a way to distill state and build per-agent briefs from a shared store, rather than threading history through call stacks.
Structured I/O between agents. Free-form text between agents drifts and gets misinterpreted. Typed inputs and outputs, schema validation, and retry-on-malformed-output belong in the harness, not in the prompt.
Termination. Loops without stop conditions run forever. Every subagent needs max iterations, token budgets, timeouts, and explicit "done" signals, enforced from outside.
Error handling. Workers fail. The orchestrator needs retry, fallback, and escalation logic. None of this comes from the model.
Observability. A single prompt loop produces one readable trace. A multi-agent system produces a tree of interleaved calls. Per-agent traces with parent-child relationships intact are what make it debuggable.
Concurrency. Parallel fan-out is only useful if the harness can actually run agents in parallel, collect results, and merge them without races in shared state.
Budget enforcement. One runaway subagent can burn a quota quickly. Per-call, per-agent, and per-task limits belong in the harness.
The takeaway
Choosing between a prompt loop, an orchestrator with subagent-tools, and a fully multi-agent system is a design decision. Whether any of those patterns actually runs well depends on the harness underneath: context construction, structured communication, termination, observability, budget enforcement. Investing in those primitives is what makes the move from a prompt loop to a multi-agent system tractable.
If you liked this, you might want to read

Introducing Brevian MCP: What If You Could Ask Your Sales Data Anything?
New intelligence, synthesized from every layer of your sales data, delivered as operational playbooks you can act on this week.
Practice the Call Before It Happens
Every high-performance profession has structured practice. Sales is the exception. Brevian Roleplays let reps rehearse deal-specific scenarios grounded in real context.

After-Call Coaching: What Should Have Been Said and Wasn't
Post-call coaching that reads the transcript in the context of the full deal. Brevian surfaces what should have been said and was not, grounded in your methodology and knowledge base.