Large language models don’t just run on code—they run on context. Unlike traditional systems, their reasoning depends on the transient information assembled at inference time. That’s why Context-Driven Design is emerging as a new paradigm: treating context assembly as a first-class architectural concern.
Context includes retrieved knowledge, domain rules, interaction history, and prompts—all curated to populate the model’s working memory (KV cache). Done well, this reduces hallucinations and latency; done poorly, it creates noise, confusion, or “context poisoning.”
Unlike Object-Oriented or Domain-Driven Design, which structure code and domains, Context-Driven Design shapes what information enters the model’s short-term memory right now. It complements existing methodologies by layering dynamic, runtime knowledge assembly on top of static software patterns.
Looking ahead, this approach will define reliable, production-grade LLM systems: aligning architecture with how models actually process information, ensuring accurate, predictable, and efficient AI applications.
Context‑Driven Design - A Design Pattern

Context‑Driven Design fills this gap by treating context assembly as a first‑class architectural concern, one which focusses on assembling the right working set of information at the moment of inference to build reliable LLM applications.

From Prompts to Context Engineering: Why LLM Applications Need a New Design Paradigm
Background
Large language models (LLMs) are transforming the way we build software, but their output quality is directly tied to the context they are given at inference time. Unlike traditional systems that operate solely on explicit parameters or static code, LLM‑based applications rely on a dynamic, composite input—what we call context—to reason effectively. As these systems move from experimental prototypes to production‑grade deployments, a gap has emerged as to how context should be assembled and delivered.
Introducing Context‑Driven Design
I see Context‑Driven Design as a new, emerging design pattern specifically for LLM‑powered systems as we go deeper into context engineering as a field of study. Existing design paradigms like Object‑Oriented Design and Domain‑Driven Design focus on how to structure code and manage domain models, but they do not address the unique runtime requirements of an LLM. In these systems, the model’s reasoning quality depends on a transient working set of information—retrieved knowledge, rules, and interaction history—streamed into the model at inference time. Without a deliberate method to curate and structure this input, applications suffer from degraded accuracy, higher latency, and unpredictable outputs.
Context‑Driven Design fills this gap by treating context assembly as a first‑class architectural concern, one which focusses on assembling the right working set of information at the moment of inference to build reliable LLM applications.
What Context Includes
Context is far more than the prompt a user types. It is a structured working set that includes retrieved knowledge chunks from a retrieval‑augmented generation (RAG) pipeline, domain‑specific facts, operational rules and guardrails, prior interaction history, and the immediate instructions provided in the prompt itself. Each of these components contributes signals that the model draws on to produce its response. Done well, this enables the model to generate accurate and grounded outputs. Done poorly, it leads to irrelevant answers, degraded accuracy, and unpredictable behavior.
How LLMs Process Context
To design this context effectively, it helps to understand how an LLM internally processes information. Modern transformer‑based models maintain a key–value (KV) cache during inference. Every processed token is stored as a pair of key and value vectors, allowing the model to attend to prior tokens without recomputing them at every step.
Conceptually, this cache is the model’s short‑term working memory. By feeding the model the right sequence of tokens, we are essentially deciding what gets written into that cache.
Why Context Must Be Balanced
The need for context arises because the LLM itself has no persistent knowledge beyond its pretrained parameters. It only “knows” what is in the current KV cache. To reason about a domain, we must populate the cache with relevant facts, prior conversation turns, and retrieval results.
However, this is a balancing act. Supplying too much data can overwhelm the model, increase latency, and dilute attention across low‑value tokens. Supplying less relevant or contradictory data leads to what can be described as context poisoning: misleading entries in the cache that the model might rely on, resulting in incoherent or incorrect outputs. Supplying too little data, on the other hand, forces the model to guess, which also reduces accuracy and increases hallucinations.
Intention driven design
The practical implication is that context must be constructed deliberately. Every token included should have a clear purpose. Retrieval pipelines must rank and filter chunks to ensure only high‑value content is surfaced.
Domain rules and compliance constraints should be encoded in a way that is concise and unambiguous. Prior conversation history should be trimmed to include only the parts that truly influence the current request.
Context is not an arbitrary concatenation of text but a curated and testable artifact that directly determines what resides in the KV cache at inference time.
Comparing to Established Design Methodologies
Traditional software engineering disciplines already offer patterns for structuring logic and data. Object‑Oriented Design (OOD) decomposes systems into objects that encapsulate state and behavior. OOD excels at modeling stable domain concepts and relationships, guiding developers to create modular, reusable components.
Context‑Driven Design differs in focus and granularity. While OOD shapes how code is structured, Context‑Driven Design shapes what information is surfaced to a reasoning engine at runtime.
In an OOD system, the central question is: Which class or method should handle this responsibility? In a Context‑Driven system, the question becomes: Which pieces of information should populate the model’s working memory right now to achieve accurate reasoning? Context‑Driven Design complements existing paradigms by layering a dynamic knowledge assembly process on top of proven software structures.
Dynamic Application of Context
Other methodologies like Domain‑Driven Design (DDD) emphasize creating ubiquitous language and bounded contexts to align code with business domains. Context‑Driven Design borrows from that idea but applies it dynamically: instead of building static models that live in source code, we build and update a transient context payload that informs an LLM on demand.
Rather than replacing established methodologies, Context‑Driven Design complements them. You still benefit from solid OOD principles in the backend systems that manage storage, retrieval, and orchestration. Those systems supply the components—knowledge chunks, rules, histories—that feed into the context. But the last mile, the assembly of that information into a carefully managed KV cache, is where Context‑Driven Design defines a new layer of architectural responsibility.
Looking Ahead
As systems evolve, this approach could become the backbone of modern LLM architectures. Our early implementations treated prompts as static blocks of text, but production systems now dynamically assemble context at runtime. They monitor output quality, refine retrieval logic through feedback loops, and adjust the composition of context over time. Guardrails are encoded as part of the context itself, rather than being bolted on as post‑processing. The result is an application that not only uses the model’s capabilities but also respects its operational constraints.
Conclusion
Treating context as a first‑class data structure leads to predictable behavior, lower latency, and reduced hallucination. By thinking in terms of how each piece of information populates the KV cache, architects can ensure that the model’s limited working memory is filled with only the most relevant tokens. In doing so, they build systems that are not just powered by LLMs but are designed to make the most of them—systems that are aligned, efficient, and ready for real‑world use.
About the Author
Anupreet Walia is the Chief Technology Officer at Brevian, where she leads AI architecture, strategy, and engineering innovation. Her work focuses on building reliable, production-grade AI systems that bridge research and real-world deployment.
References
Wang, H. et al. Context‑Aware AI Systems with LLMs: Architectural Insights. Prompts.ai, 2024. Link
Patel, R., & Nguyen, T. Retrieval‑Augmented Generation Pipelines and Context Design. Proceedings of NeurIPS, 2023. Link
Vaswani, A. et al. Attention is All You Need. NeurIPS, 2017. Link
Chen, P. Practical Transformer Usage: KV Cache as Working Memory. AI Engineering Blog, 2023. Link
Lee, S. Challenges in Context Window Management for LLMs. ICML Workshop on NLP Systems, 2024. Link
Kim, D., & Zhao, L. Testable Artifacts in Context Engineering. AAAI Conference, 2024. Link
Garcia, R. Bridging Software Design and LLM Runtime Architecture. Software Engineering Notes, 2024. Link
If you liked this, you might want to read
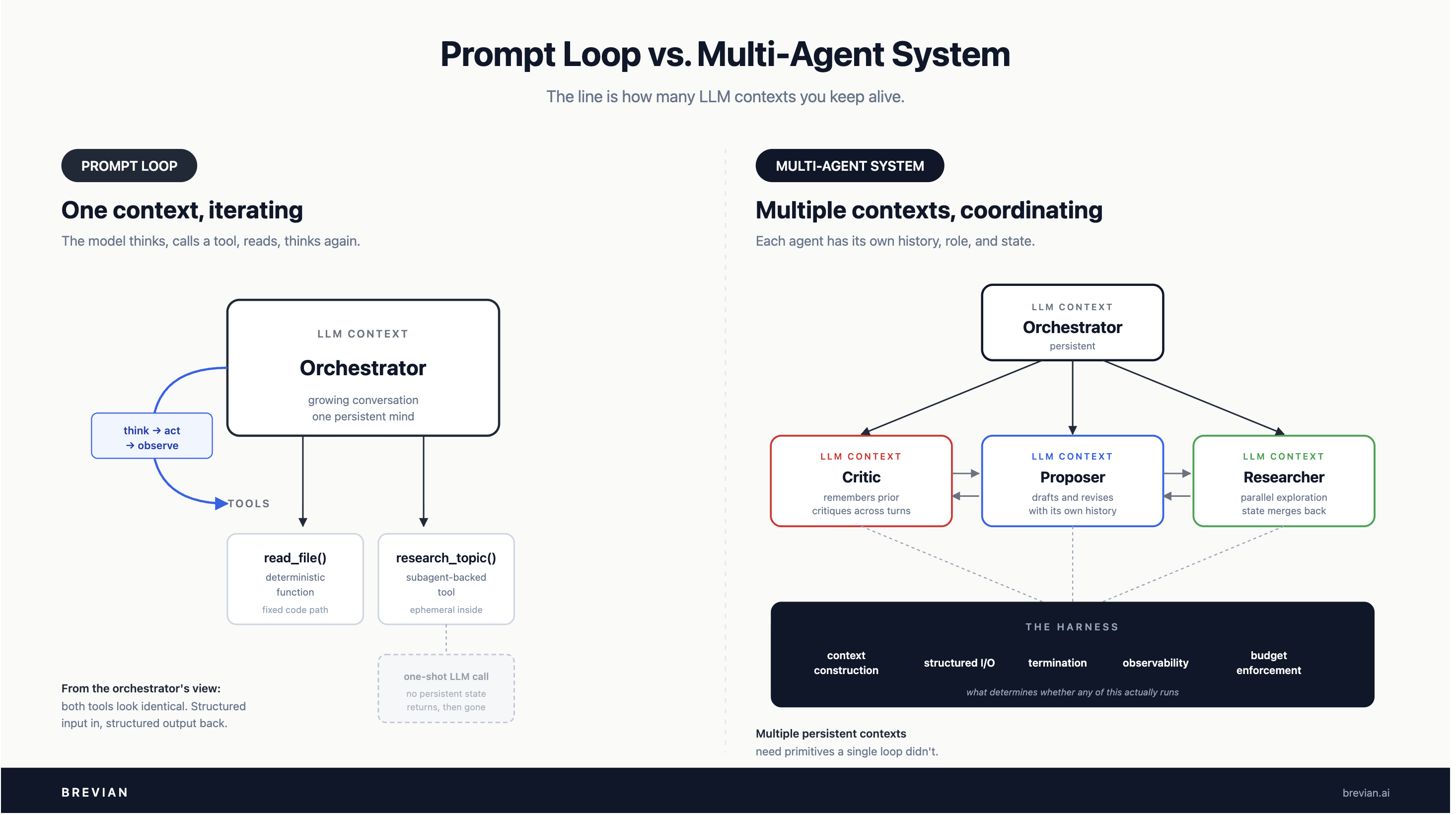
From Prompt Loops to Multi-Agent Systems: Why the Harness Matters
Where the line between a prompt loop and a multi-agent system actually sits, and what that implies for the harness you have to build underneath.

Introducing Brevian MCP: What If You Could Ask Your Sales Data Anything?
New intelligence, synthesized from every layer of your sales data, delivered as operational playbooks you can act on this week.
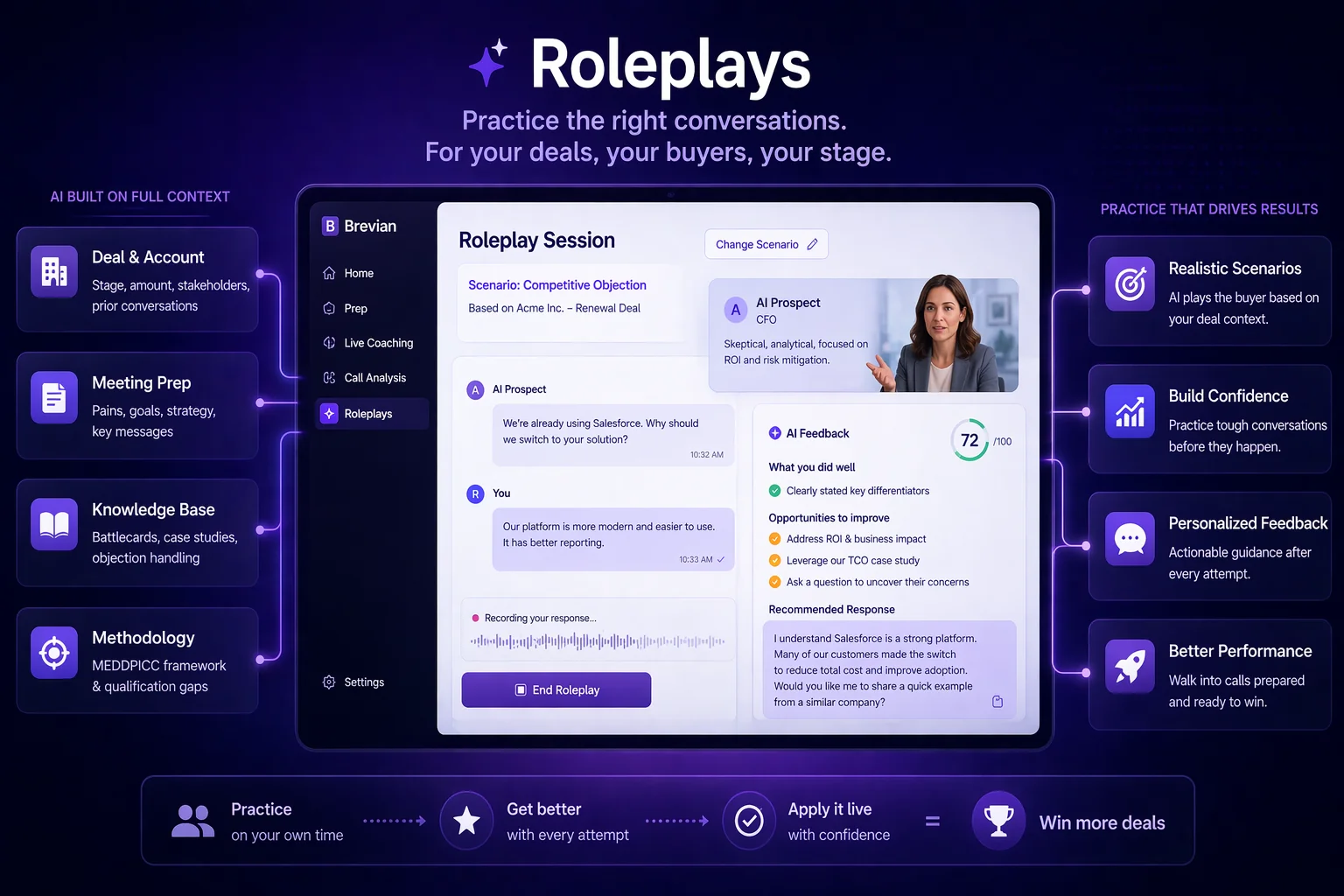
Practice the Call Before It Happens
Every high-performance profession has structured practice. Sales is the exception. Brevian Roleplays let reps rehearse deal-specific scenarios grounded in real context.