At Brevian, prompts are treated as production-grade software, held to standards of reliability, observability, and maintainability. Early deployments revealed that prompts are fragile, tightly coupled to models, and prone to hallucinations without clear structure. To address this, Brevian applies a 3-Pass Rule:
Automatic Prompt Optimization (APO): Iteratively tuning prompts against curated datasets using reinforcement learning.
Guardrails & Constraints: Adding explicit rules to enforce scope, tone, and safe handling of edge cases.
Evals & Runtime Observability: Continuously testing outputs in CI/CD and live environments to catch drift, hallucinations, and regressions.
This disciplined engineering approach ensures prompts evolve safely with models and datasets, remaining testable, predictable, and resilient—just like any other mission-critical system.
Building Reliable Prompts

At Brevian, prompts are treated as a first‑class engineering artifact. Every prompt that powers our AI systems is expected to meet the same standards of reliability, observability, and maintainability as any other production software component.

Automatic Optimization, Guardrails, and Evals: Building Trustworthy Prompts at Scale
At Brevian, prompts are treated as a first‑class engineering artifact. Every prompt that powers our AI systems is expected to meet the same standards of reliability, observability, and maintainability as any other production software component.
To give a little background, we had a few realizations very quickly after deploying our first few prompts to production. First, the prompts are fickle and very tightly coupled to the underlying model/LLM. Second, the prompts need to be designed for “what good looks like”. The LLMs are really good at generating content even at the expense of facts. Few-shot prompting with examples didn’t work given that the language models start imitating the pattern of behavior almost to comical inaccuracy. Third, the structured json output has come a long way but you still need to prompt it well to ensure the constraints your apis have downstream are correctly reflected.
To achieve this, we follow a structured 3‑Pass Rule when designing and deploying prompts. This process combines automatic optimization, guardrails, and continuous evaluation to ensure consistency and correctness over time.
Pass 1: Automatic Prompt Optimization (APO)
We begin with APO — Automatic Prompt Optimization.
A curated test dataset is created that contains a representative set of inputs along with their expected outputs and required formatting rules. The prompt is iteratively tuned against this dataset until it meets predefined success criteria across all test cases using reinforcement learning. This allows us to build prompts that are validated against real product use cases rather than ad‑hoc examples.
Pass 2: Guardrails and Constraints
After the initial optimization, guardrail instructions are added. These explicitly define constraints and expected behaviors, such as:
- Maintaining output within a specified scope and tone.
- Handling incomplete or ambiguous inputs by prompting for clarification.
- Avoiding irrelevant, unsafe, or non‑compliant responses.
This phase ensures that prompts exhibit predictable behavior even under unexpected or edge‑case inputs.
Pass 3: Evals and Runtime Observability
Finally, prompts are placed under evals—automated evaluation suites that continuously verify outputs both during CI/CD and in runtime environments. These evaluations:
- Compare live outputs against expected patterns.
- Surface exceptions when hallucinations or format deviations are detected.
- Include dedicated edge‑case inputs to identify regressions or model drift over time.
With this, prompts remain stable and trustworthy, with drift or unexpected behavior detected before reaching end users.
For engineers accustomed to traditional software systems, the 3‑Pass Rule maps naturally to established engineering disciplines. In classical system engineering we strive for a system that is observable, testable, and resilient. One which handles expected workloads correctly, fails gracefully under unexpected conditions, and provides clear signals when something is wrong. And in practice, we build this with strong validation test suites, well‑defined interfaces, and thorough monitoring with dashboards. We are adapting these principles to prompts and we see similar results. We solve for:
- Model drift: Continuous evaluation highlights subtle shifts in model behavior.
- Hallucinations: Outputs are checked against expected patterns, with deviations flagged.
- Runtime exceptions: Guardrails and evals catch failure modes before they affect end users.
- Edge‑case errors: Dedicated test inputs ensure consistency under stress conditions.
Prompts are not static artifacts. They evolve alongside models, datasets, and user needs. By applying disciplined engineering practices—APO, guardrails, and evals—we ensure that every prompt deployed at Brevian is rigorously tested, observable in production, and resilient to change.
About the Author
Anupreet Walia is the Chief Technology Officer at Brevian, where she leads AI architecture, strategy, and engineering innovation. Her work focuses on building reliable, production-grade AI systems that bridge research and real-world deployment.
References
Teki, S. Prompting is the New Programming Paradigm in the Age of AI. Personal Blog, 2023. Link
Prompt Engineering Guide. Few-Shot Prompting. PromptingGuide.ai, 2023. Link
QED42. Building Simple & Effective Prompt-Based Guardrails. QED42 Insights, 2024. Link
Humanloop. Structured Outputs: Everything You Should Know. Humanloop Blog, 2023. Link
Wolfe, C. Automatic Prompt Optimization with Reinforcement Learning. Substack, 2023. Link
If you liked this, you might want to read
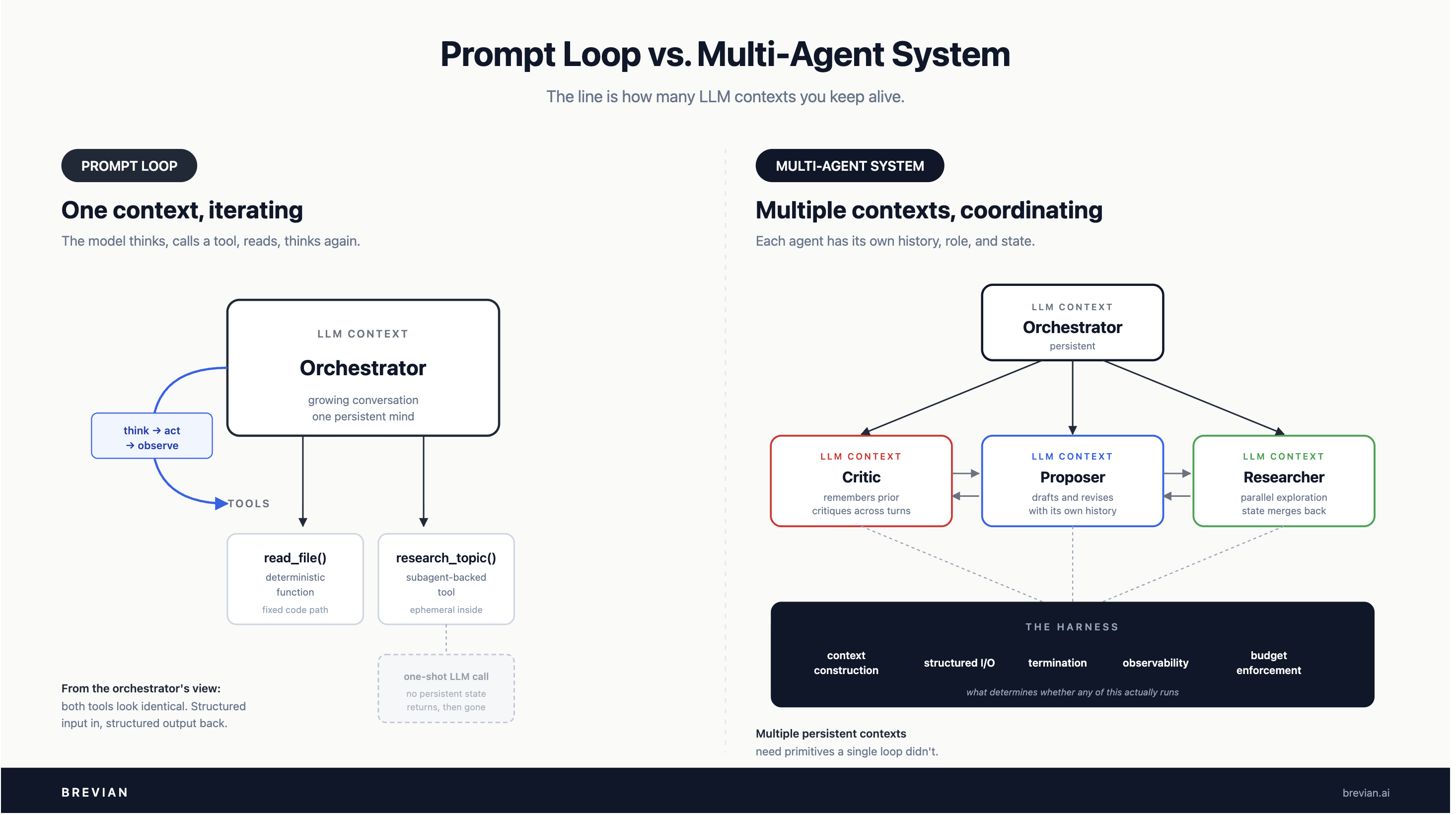
From Prompt Loops to Multi-Agent Systems: Why the Harness Matters
Where the line between a prompt loop and a multi-agent system actually sits, and what that implies for the harness you have to build underneath.

Introducing Brevian MCP: What If You Could Ask Your Sales Data Anything?
New intelligence, synthesized from every layer of your sales data, delivered as operational playbooks you can act on this week.
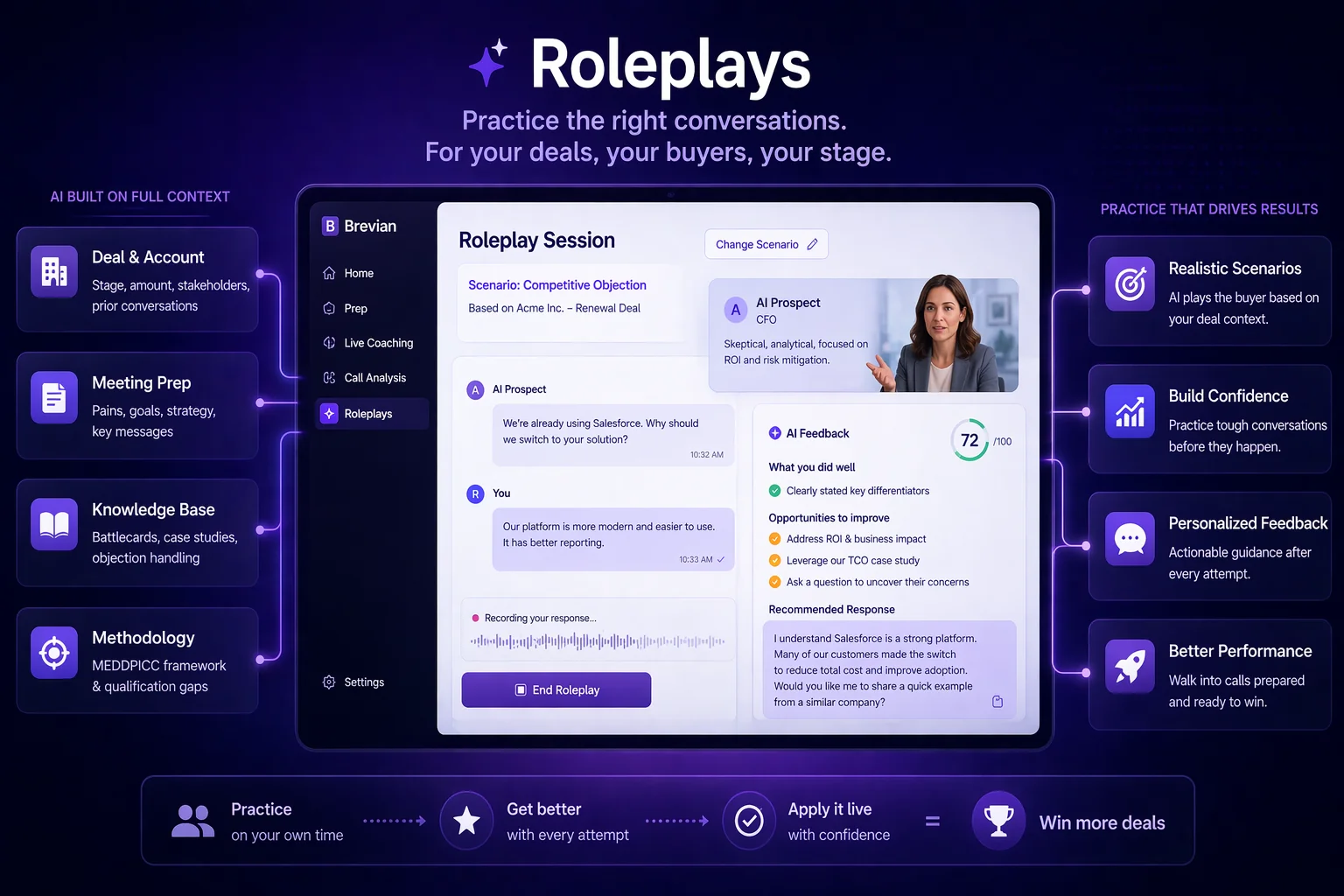
Practice the Call Before It Happens
Every high-performance profession has structured practice. Sales is the exception. Brevian Roleplays let reps rehearse deal-specific scenarios grounded in real context.